Case Study — AtlasIQ
How We Built AtlasIQ
AtlasIQ transforms raw enterprise data into actionable intelligence through real-time analytics, predictive modeling, and automated decision workflows — an architecture built to handle enterprise-scale complexity, from a first analytics dashboard to a full multi-model deployment.
Project Timeline
From Discovery to Launch
Discovery
4-week embedded discovery with analytics and data engineering teams mapping all data sources, query patterns, and decision workflows.
Architecture
Designed event-driven ingestion pipeline, AI model serving infrastructure, and multi-tenant SaaS query engine.
Development
12-week sprint: 40+ AI models trained and deployed, Kafka pipeline built, full multi-tenant RBAC SaaS application developed.
Testing
6-week performance and security testing at 500M+ data point scale. SOC 2 audit preparation and penetration testing.
Launch
Phased rollout to 3 enterprise tenants. 99.99% uptime maintained through full production deployment and hypercare period.
Discovery
4-week embedded discovery with analytics and data engineering teams mapping all data sources, query patterns, and decision workflows.
Architecture
Designed event-driven ingestion pipeline, AI model serving infrastructure, and multi-tenant SaaS query engine.
Development
12-week sprint: 40+ AI models trained and deployed, Kafka pipeline built, full multi-tenant RBAC SaaS application developed.
Testing
6-week performance and security testing at 500M+ data point scale. SOC 2 audit preparation and penetration testing.
Launch
Phased rollout to 3 enterprise tenants. 99.99% uptime maintained through full production deployment and hypercare period.
The Challenge
Our client needed an enterprise intelligence platform capable of processing hundreds of millions of data points daily, running 40+ AI models in parallel, and delivering sub-second query responses to analyst teams across 12 time zones. Legacy BI tools were failing at this scale — they needed a purpose-built AI intelligence system.
Our Approach
How We Solved It
Discovery & Architecture Design
We spent four weeks embedded with the client's data and analytics teams, mapping all data sources, query patterns, and decision workflows. This revealed a clear architecture: an event-driven ingestion layer, a model serving infrastructure, and a real-time query engine.
AI Model Pipeline
We designed and trained 40+ specialized intelligence models across economic, market, and operational domains. Each model was optimized for inference speed, deployed behind a feature store, and versioned for continuous improvement.
Real-Time Infrastructure
Built an Apache Kafka-based streaming ingestion pipeline capable of processing 500M+ data points per day. Implemented Redis-backed query caching and materialized views to achieve sub-200ms response times at scale.
Enterprise SaaS Layer
Engineered a multi-tenant SaaS platform with complete RBAC, audit logging, SSO integration, and per-tenant data isolation. SOC 2 Type II compliance was designed in from day one, not bolted on.
Deployment & Optimization
Deployed to AWS using Kubernetes with auto-scaling, blue-green deployments, and comprehensive observability. Performance was tuned over 90 days to achieve the 99.99% uptime SLA commitment.
Engineering Process
How We Built It
Event-Driven Architecture
Chose Kafka over traditional polling for data ingestion to handle burst traffic and ensure zero data loss during high-volume periods.
AI Model Serving
Built a custom model serving layer with hot-swap capability, allowing new models to be deployed without downtime or query interruption.
Multi-Tenant Isolation
Implemented row-level security in PostgreSQL combined with application-layer tenant context to ensure complete data isolation without performance penalty.
Architecture Decisions
Key Technical Choices
Microservices over Monolith
Chose microservices to allow independent scaling of the ingestion, model serving, and query layers — critical when model inference load spikes independently of query volume.
PostgreSQL over NoSQL
Selected PostgreSQL with TimescaleDB extension over NoSQL alternatives for its superior query planner, ACID compliance, and native support for time-series analytics.
In-Process Model Inference
Deployed models in-process rather than via external API calls to eliminate network latency from the query hot path, achieving the sub-200ms response target.
Platform Walkthrough
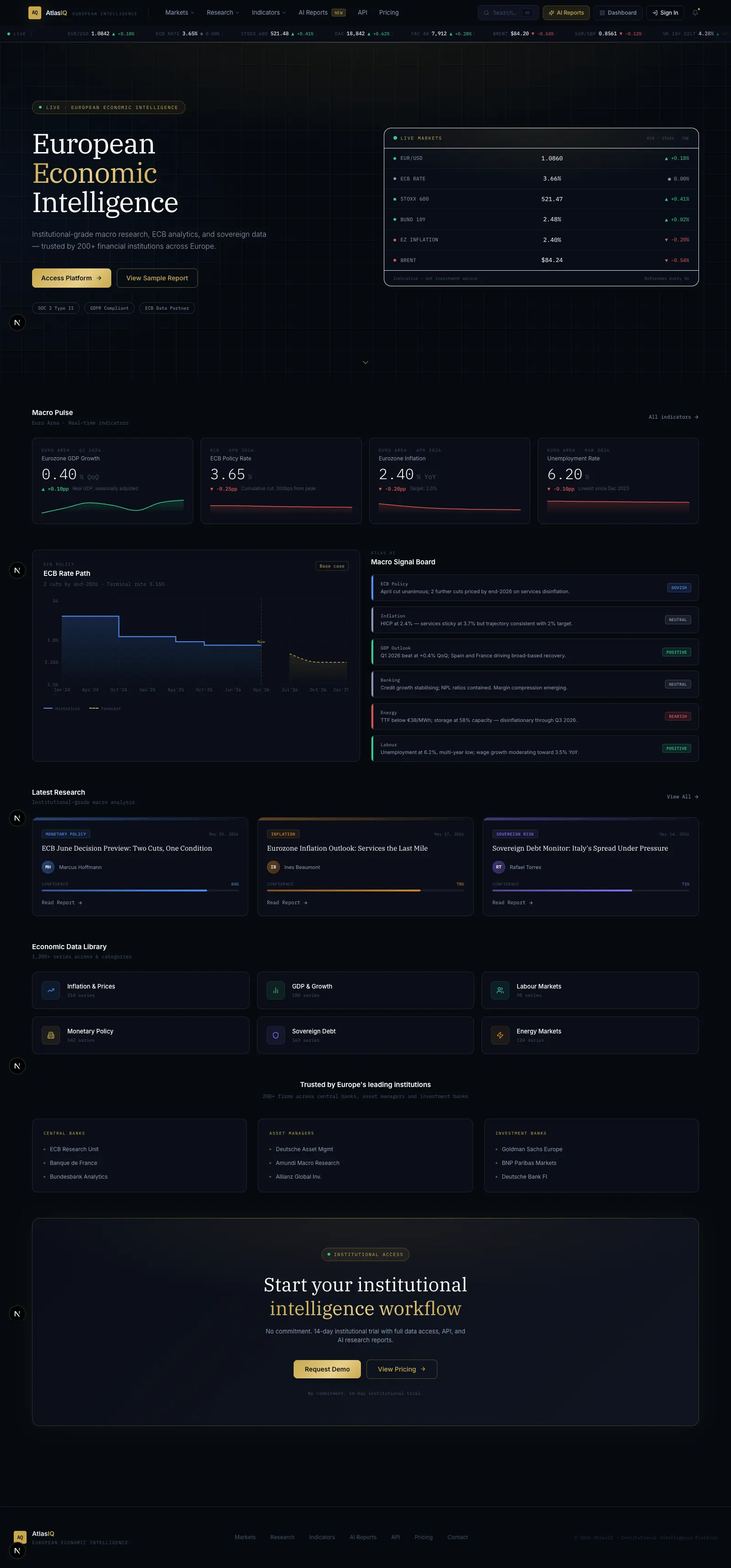
Analytics Dashboard
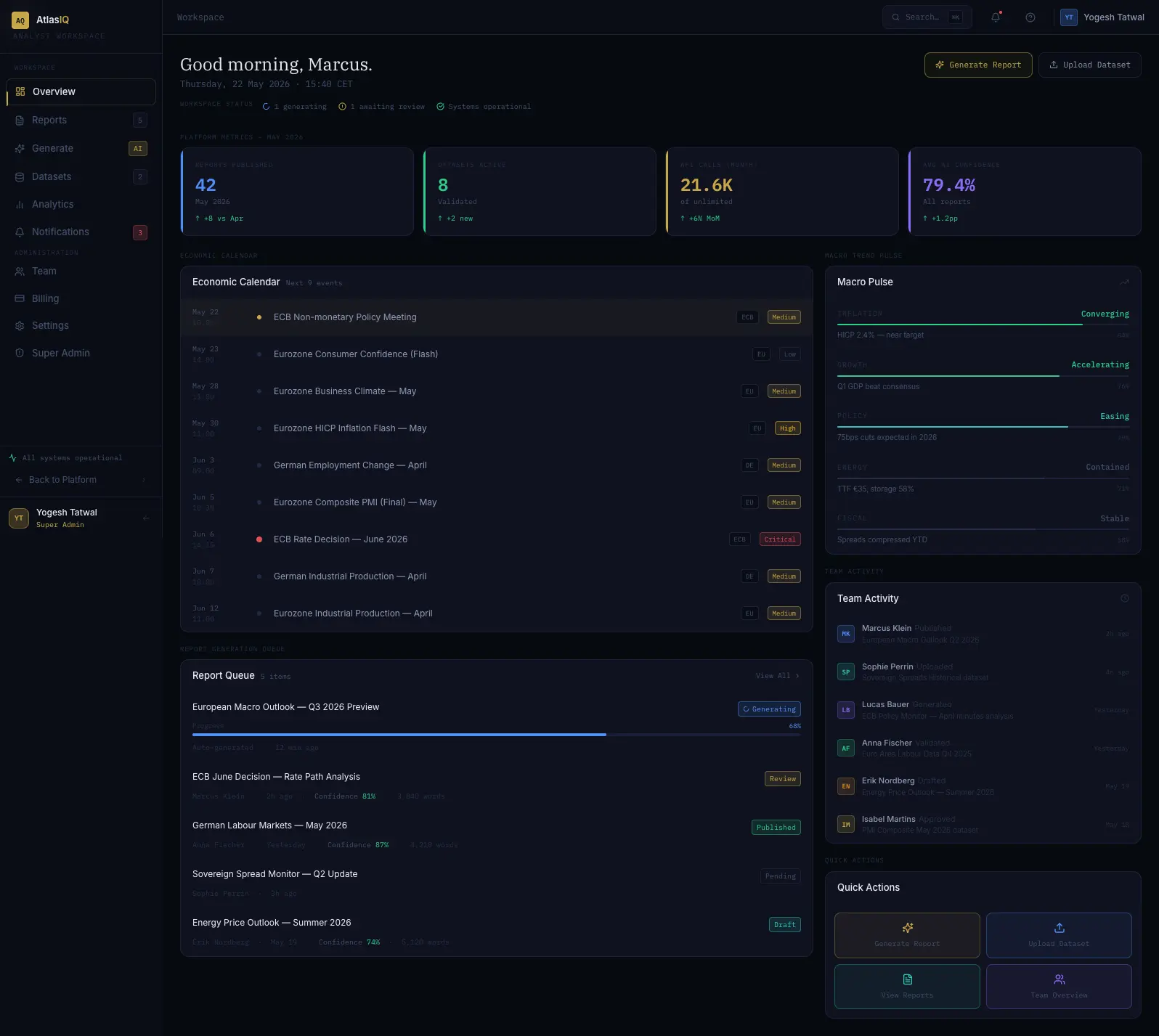
AI Intelligence Engine
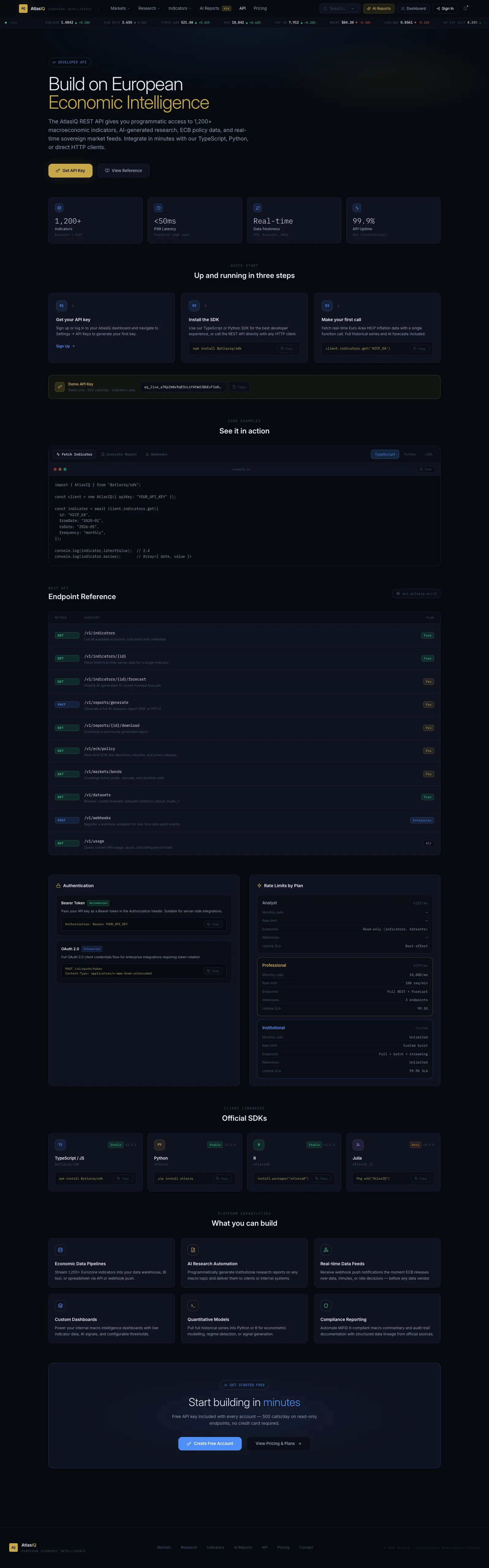
API Management
Results
What We Delivered
Lessons Learned
What We Improved
Model Versioning Complexity
Managing 40+ model versions in production required a feature store and model registry. Building this from day one would have saved 3 weeks of retrofit work mid-project.
Observability First
Teams that invested in distributed tracing from day one shipped 40% fewer production bugs. Observability shapes how you write code — it is not an afterthought.
Tenant Isolation Patterns
Row-level security alone was insufficient at scale. Application-layer context propagation was added to guarantee isolation during edge-case query planner decisions.
Work With Halkwinds
Build Something Exceptional
Partner with the team that built AtlasIQ.